회사 첫 프로젝트에서 Mybatis를 사용하다가 두번째 프로젝트에서 JPA를 사용하게 되어서 약 한달간 김영한님 강의에서 부족한 내용을 보충하고 요약하여 정리해보았다.
강의 주소는 아래와 같으며 사진의 출처또한 강의에서 제공한다.
https://www.inflearn.com/course/ORM-JPA-Basic/dashboard

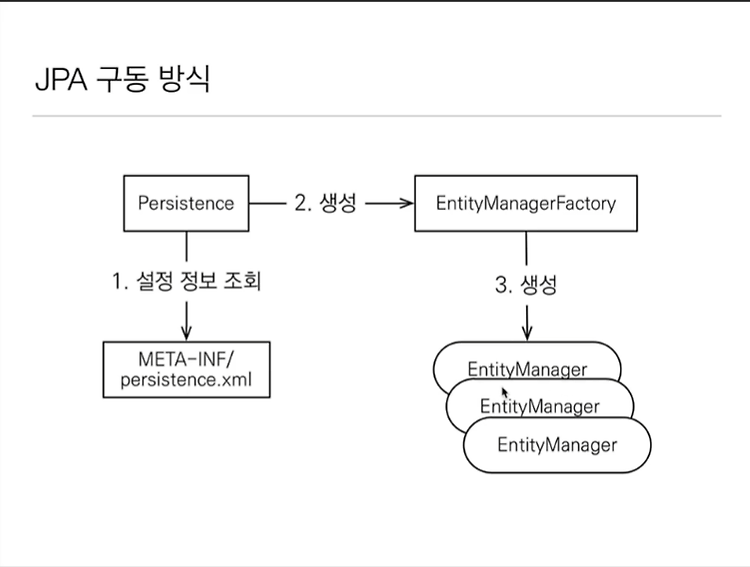
기본적인 JPA 코드
// 엔티티 매니저 팩토리 생성
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
// 엔티티 매니저 생성
EntityManager em = emf.createEntityManager();
// 트랜잭션 생성
EntityTransaction tx = em.getTransaction();
// 트랜잭션 시작
tx.begin();
try{
Member member = new Member();
member.setId(1L);
member.setName("HelloA");
em.persist(member);
// 트랜잭션 커밋
tx.commit();
}catch (Exception e){
// 트랜잭션 롤백
tx.rollback();;
}finally {
// 엔티티 매니저 close (무조건 필수)
em.close();
}
// 엔티티 매니저 팩토리 close
emf.close();엔티티 매니져 팩토리는 무조건 한 애플리케이션 하나당 하나이다.

모든 테이블을 객체로 쥐고 있을수 없으므로 결국 쿼리를 써서 필요한 객체만 가져와야함
따라서 JPQL을 사용함
JPQL : 테이블이 아닌 객체를 대상으로 검색하는 객체 지향 쿼리 , 한마디로 정의하자면 객체 지향 SQL
JPA에서 가장 중요한 두가지
- 객체와 관계형 데이터베이스 매핑하기
- .영속성 컨텍스트
영속성 컨텍스트
- 엔티티를 영구 저장하는 환경
- EntityManager.persist(entity); -> 이것은 DB에 저장하는것이 아닌, 영속성 컨텍스트에 저장한다는 소리임
엔티티의 생명주기
- 비영속 : 영속성 컨텍스트와 전혀 관계 없는 새로운 상태
// 객체를 생성한 상태 (비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
- 영속 : 연속성 컨텍스트에 관리되는 상태
// 영속
em.persist(member);
- 준영속 : 영속성 컨텍스트에 저장되었다가 분리된 상태
em.detach(member);
- 삭제 : 삭제된 상태
em.remove(member);
영속성 컨텍스트의 이점
1.1차 캐시

엔티티매니저(대충 영속 컨텍스트라고 생각)를 persist하게되면 1차 캐시에 위와 같이 ID와 엔티티 객체 자체를 가지고 있음 따라서 나중에 다시 회원1을 조회하게 되면 DB를 갔다오지 않고 1차 캐시에서 바로 가져옴

그후 1차 캐시에 없는 회원2를 조회하면 DB를 조회하게되며, 조회한 결과는 1차 캐쉬에 저장된다.
1차캐시는 한 트랜잭션안에서만 동작하고 끝나면 사라지기 때문에(찰나의 시간에 작동하기 때문에) 실제로 현업에서 큰도움은 되지않는다고 한다.
2.동일성 보장

마치 JAVA Collection에서 꺼내서 쓰듯이 동일 트랜잭션 안에서 같은 객체는 동일성이 보장된다.
3.트랜잭션을 지원하는 쓰기 지연

위 사진처럼 em.persist()에서 바로 insert sql을 보내지 않는다면
마지막에 트랜잭션 커밋때 어떻게 두번의 insert가 날라갈까?

그것은 위 사진처럼 "쓰기 지연 SQL 저장소"라는 것이 존재하여 sql을 차곡차곡 쌓아둔다
그 후, 트랜잭션을 커밋하는 시점에 아래와 같이 실제 데이터베이스에 반영된다.

4.변경 감지

가장 먼저 찾았을때 스냅샷에 해당 엔티티 정보를 저장해뒀다가
트랜잭션이 커밋되는 시점에 스냅샷과 엔티티를 비교하여 값이 다르다면
UPDATE SQL을 쓰기 지연 SQL 저장소에 생성한뒤 DB에 반영한다.
즉, 자동으로 업데이트된다.
그런데 자주 사진에서 보이는 flush()는 무엇인가?
플러시 : 영속성 컨텍스트의 변경내용을 데이터베이스에 반영하는것
플러시 발생시 일어나는 일
1.변경 감지
2.수정된 엔티티 쓰기 지연 SQL 저장소에 등록
3.쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
Q.플러시를 하게되면 1차 캐시가 지워지나요?
->아님, 위에 있는 순서대로 DB에 전송까지 되고, 트랜잭션이 끝나는게 아니기에 1차 캐시는 지워지지 않는다.

JPQL쿼리 실행시 플러시가 자동으로 호출됨.
그 이유는 위와같이 memberA,B,C를 insert한다고 가정할때, 영속성 컨텍스트에만 넣어놓고 JPQL을 실행했을때,
아직 커밋전이기에 Member에 저장된 데이터가 없어서 query는 아무것도 조회하지 못할수있다.
따라서 JPQL실행전에 플러시가 자동으로 호출된다.
그럼 만약 A,B,C를 앞에서 조회해서 1차캐시에 존재하는데 JPQL을 실행하면 이미전부 1차캐시에 있으니 조회가 안되나?
-> 잘못된 생각임 1차 캐시는 앞 그림과 같이 ID와 함께 가지고있으며, ID를 조회해야 1차 캐쉬에 있는 객체를 가져올수있음 JPQL은 sql문을 던지기때문에 ID를 조회하는것과 결이 다르다.
5.지연 로딩
양방향 매핑
양방향 매핑 시 연관관계의 주인을 정해야함
연관관계의 주인은 항상 '외래 키 위치를 기준'으로 정한다.
비지니스 로직을 기준으로 주인을 선택하는것보다 위가 좀더 관리가 용이하고 성능에서 뛰어나다.
만약 주인이 아닌곳에서 insert문을 실행한다면?
try {
Member member = new Member();
member.setUserName("member1");
em.persist(member);
Team team = new Team();
team.setName("TeamA");
team.getMembers().add(member);
em.persist(team);
em.flush();
em.clear();
// 트랜잭션 커밋
tx.commit();
}catch (Exception e) {
tx.rollback();
}finally {
em.close();
}
위에서 team.getMembers().add(member);를 하게되면 즉, 주인이 아닌 Team 엔티티에 가짜매핑되어 있는 Members에 insert하게 된다면 DB에는 TEAM의 정보가 들어가지 않게된다.


위처럼 INSERT쿼리는 두번 정상적으로 호출하지만, 정작 DB에는 TEAM정보가 없다.
따라서 연관관계의 주인이 있는곳에서 호출해서 넣어줘야한다
try {
Team team = new Team();
team.setName("TeamA");
// team.getMembers().add(member);
em.persist(team);
Member member = new Member();
member.setUserName("member1");
member.setTeam(team); // 추가
em.persist(member);
em.flush();
em.clear();
// 트랜잭션 커밋
tx.commit();
}catch (Exception e) {
tx.rollback();
}finally {
em.close();
}
위와 같이 연관관계의 주인이 있는 MEMBER에서 member.setTeam(team)하게 되면 db에 정상적으로 들어오는 것을 확인할 수 있다.
* 연관관계의 주인이 아닌 반대편은 외래 키에 영향을 주지 않고, 단순 조회만 한다.
여기서 단방향 연관관계로 본다면 위의 방식이 맞다고 생각할수있다.
그러나 양방향 연관관계는 두 객체의 연관컬럼을 모두 셋팅해줘야한다.
즉, 객체의 관점에서 모두 설정해주는 것이 맞다.
아래 예시를 보자
try {
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUserName("member1");
member.setTeam(team);
em.persist(member);
// em.flush();
// em.clear();
Team findTeam = em.find(Team.class , team.getId()); // 1차 캐시
List<Member> members = findTeam.getMembers();
for(Member m : members){
System.out.println(" m = " + m.getUserName());
}
// 트랜잭션 커밋
tx.commit();
}catch (Exception e) {
tx.rollback();
}finally {
em.close();
}위에서 flush()와 clear()를 주석처리한다면 아래의 m.getUserName()이 찍힐까?

아무것도 찍히지 않는것을 확인할 수 있다.
즉 , 위 코드에선 1차캐시에 방금 만들어진 순수객체가 들어있을뿐 flush를 거치지 않으면 순수객체는 서로 연관되어있지 않은상태이다.
따라서, 아래와 같이 수정해준다.
try {
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUserName("member1");
member.setTeam(team);
em.persist(member);
team.getMembers().add(member); // 추가
// em.flush();
// em.clear();
Team findTeam = em.find(Team.class , team.getId()); // 1차 캐시
List<Member> members = findTeam.getMembers();
for(Member m : members){
System.out.println(" m = " + m.getUserName());
}
// 트랜잭션 커밋
tx.commit();
}catch (Exception e) {
tx.rollback();
}finally {
em.close();
}team.getMembers().add()를 사용하여 양방향으로 매핑을 해준다면

m = member1이 찍히는 것을 볼 수있다.
즉 ,순수 객체 관점(객체 지향 관점)에서 본다면 서로 매핑해주는 것이 옳다.
그렇다면, 양방향 매핑관계가 있을시 항상 위처럼 셋팅해주는것이 귀찮지않나?
해결방안으로 아래와같이 연관관계 편의 메서드를 정의한다.
// 연관관계 편의 메서드
public void setTeam(Team team){
this.team = team;
team.getMembers().add(this);
}// 연관관계 편의 메서드
public void addMember(Member member){
member.setTeam(this);
members.add(member);
}위처럼 TEAM 또는 MEMBER 둘 중 하나에 상황을 고려하여 연관관계 편의 메서드를 정의한다.
양방향 매핑시 주의 해야할점은 toString(),lombok 사용시 무한 루프에 빠질수 있기때문에 유의하여 사용한다.
결론 : 최대한 단방향을 지향하되, JPQL과 같은 쿼리를 짜거나, 비지니스적인 관점이 들어갈때 양방향을 사용한다.
* 다대다 매핑
김영한 교수님 피셜 "다대다는 실무에서 쓰면 안된다. 실패한 설계다"


1.실무에선 단순히 연결만 하고 끝난지않는다.
2. 주문시간 ,수량같은 데이터를 연결 테이블에 삽입할 수가 없음. ( 필드 추가가 안됨 )
3. 매핑 테이블로 인해 생각지도 못한 쿼리가 나감.

다대다 한계를 극복하려면 위와같이 연결 테이블을 엔티티로 승격하여 사용할 수 있다.
* DB 키값 설계 팁

위 사진처럼 2개의 FK를 KEY로 가지는 db가 있고,

위 사진처럼 PK를 하나 두고, 두가지의 FK를 조인용도로만 두는 DB가 있다.
어떤것이 답이라 할순없지만 보통 교수님이 실무에서 직접 느끼신건 PK를 직접 따로 두는게 편하다고 말씀하셨다.
보통 모든 테이블에 GenerateValue를 둔다고 하신다.
PK를 따로 두지않으면 그 순간에 제약조건을 둘때는 괜찮은데,
어플리케이션이 커짐에따라서 유연성이 중요해짐에따라 PK하나만 둔것에 비해 JPA매핑도 심플하지 못하고, 어플개발이 유연하지않고 어려워진다고 하신다.
* 프록시

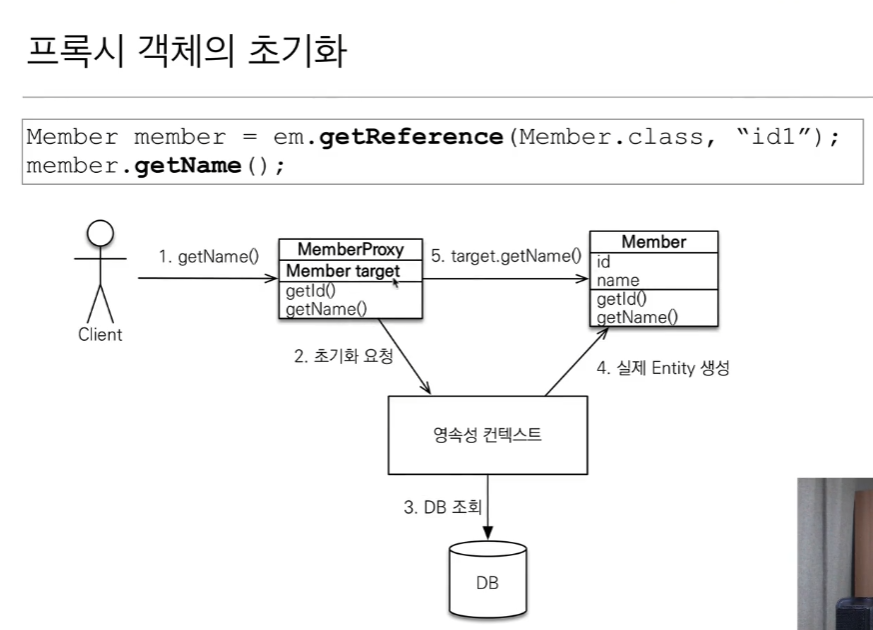

JPA에서 entity타입 비교시 ==가 아닌 instance of를 사용해야함
프록시객체와 실제 엔티티가 엇갈릴수 있기때문
"영속성 컨텍스트에 찾는 엔티티가 있으면 em.getReference()를 호출해도 실제 엔티티 반환" 예시
* 선수지식
.find() = 실제 객체를 찾는다.
.getReference() = 프록시 객체를 찾는다.
1.실제 객체를 먼저 찾고, 프록시 객체를 찾는 경우

영속성 컨텍스트의 특징중 하나는 동일성을 보장하는것이다.
조회된 두 객체가 실제 객체와 프록시 객체일지라도 동일한 PK를 가져오기때문에
위 결과는 둘다 똑같이 실제 엔티티 클래스를 반환한다.
즉, getReference()를 썼더라도 영속성 컨텍스트에 이미 찾는 엔티티가 있기때문에 실제 엔티티가 반환된다.

결과로 a == a 는 TRUE가 나오게된다.
JPA는 한 영속성 컨텍스트내에서 동일한 PK를 가져오면 항상 TRUE를 반환해줘야한다.
한 트랜잭션내에서 동일성을 보장하는 JPA의 매커니즘이라고 볼수있다.
그렇다면 반대로 아래의 경우는?
2. 프록시 객체를 먼저 찾고, 실제 객체를 찾는 경우

refMember 프록시 객체가 먼저 조회되고, 실제 객체로 덮여씌워질까?라고 생각을 해볼수있다.
그러나 결론은 둘다 Proxy 객체가 조회된다.
따라서 refMember == findMember는 TRUE를 반환한다.
위 예제는 프록시 객체와 실제 객체가 동일한 PK를 조회할경우, 먼저 조회된 객체로 통일 시켜주는 모습과 트랜잭션내에서 동일성을 무조건적으로 보장하는 JPA의 특성을 잘 보여준다.
*실전에서 매우 자주 마주치게 되는 경우

위에서 refMember의 프록시 객체를 조회한후. detach() (해당 객체를 영속성 컨텍스트에서 꺼냄) 이나 clear()(영속성 컨텍스트를 초기화함) 등등을 한후 조회하게되면?

위와 같이 LazyInitialIzationException을 마주치게 된다. 따라서 위 오류가 떴을때, 프록시 객체가 영속성 컨텍스트에 없는 경우라고 예측할수 있다.
* 즉시로딩과 지연 로딩
지연 로딩은 프록시 객체를 조회하는것이며, 즉시 로딩은 실제 객체를 바로 가져온다.


만약 MEMBER와 TEAM이 즉시 로딩상태일때,
위 결과는 MEMBER를 SELECT하는 쿼리 한번 , TEAM을 SELECT 하는 쿼리가 한번씩 나가게 된다.
JPQL은 실제 SQL문을 작성하는 것이기때문에 MEMBER를 조회한후 TEAM이 EAGER로 설정되어 있기때문에 뒤늦게 TEAM을 다시 조회하기 때문이다.
아래 예시를 보자

위와 같이 각각 두개의 멤버와 팀을 정의한후,
멤버1은 팀A에 , 멤버2는 팀B에 배치시킨다.

위 JPQL문을 실행하게 되면?

우선 MEMBER를 조회하고,

두개의 TEAM쿼리가 나가게된다.
MEMBER를 조회했을때, 각 멤버는 팀이 서로 다르며, 영속성 컨텍스트에도 해당 내용이 없기때문에(clear()해줬기때문)
모든 TEAM을 찾는 쿼리가 나가게 되는것이다.
즉, N을 위에서 TEAM이라고 보고, 1을 MEMBER라고 볼때 N+1문제가 발생할 수 있다.
* CASCADE와 고아객체
CASCADE 옵션중 CascadeType.ALL만 주로 사용한다.
고아객체는 orphanRemovel=true로 활성화 가능하며, 만약 두가지 모두 true를 주게된다면
부모 엔티티를 통해서 자식의 생명 주기를 관리할 수 있다.
부모가 생성되면 자식도 생성되고, 부모가 삭제되면 자식도 삭제된다.
따라서 자식의 생명주기를 관리할 수 있다.
CASCADE와 고아객체 둘다 모두 하나의 소유자만 가질때 사용해야한다.
예를들어 게시물이있고 게시물에연결된 url이 들어갈 첨부파일을 관리하는 테이블을 예시로 들수있다.
만약 첨부파일 테이블이 게시물이 아닌 다른곳에도 사용된다면 사용하지 않아야 한다.
* 임베디드 타입
여러개의 필드를 하나의 객체로 묶어 다른 엔티티에서 해당 객체를 필드로 사용할 수 있다.
임베디드 타입의 장점
(사용하는쪽에서 @Embedded 또는 실제 테이블에서 @Embeddable 써야하는데 택1 그러나 둘다 쓰는것을 권장)
응집성이 높아짐
* 잘 설계한 ORM 어플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많음

임베디드 클래스를 재사용 하려면 위와같이 @AttributeOverrides를 이용해 컬럼명만 설정하여 재사용할 수 있다.
만약 동일한 임베디드 필드가 있다면 오류가 뜨고, 임베디드 객체가 NULL이라면 임베디드 필드는 모두 NULL로 설정된다.
그러나 임베디드는 "값타입"이기 때문에
값 타입의 실제 인스턴스 값을 공유하는 것은 위험하다.
아래는 두가지 차이점을 잘 보여주는 예제이다.
int a =10;
int b= a; // 기본 타입은 값을 복사
b = 4;Address a = new Address("Old");
Address b = a; // 객체 타입은 참조를 전달
b.setCitry("New")
primitive타입은 항상 값이 복사되어 넘어가지만, 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이아닌 객체 타입이기 때문에 참조 값을 직접 대입하는것을 막을 방법이 없다.
"객체의 공유 참조는 피할 수 없다."
따라서 새로운 임베디드 인스턴스를 생성하여 사용한다. 즉 , 복사하여 사용해야 한다.
아니면 불변객체로 사용해야 한다.
불변객체로 사용하기 위해서 setter를 모두 지우고, 생성자로만 생성하여 사용하면 된다.
* 값 타입 컬렉션
값 타입을 하나 이상 저장할때 사용
@ElementCollection, @CollectionTable 사용
데이터베이스는 컬렉션을 같은 테이블에 저장할 수 없음.

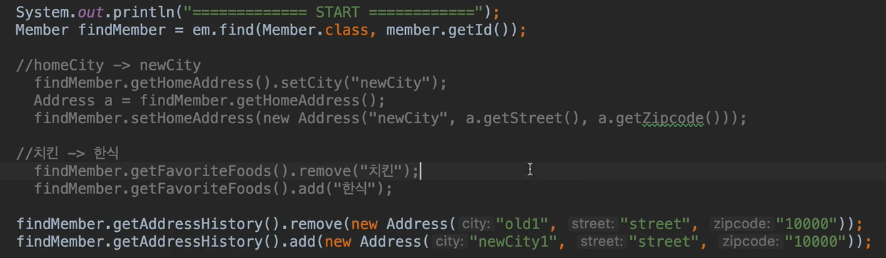
위는 값타입 컬렉션을 수정하는 사례이다.
.remove()는 보통 자바 컬렉션 특성상 내부에서 .equals()로 동작하기때문에 클래스에서 직접 .equals()를 정의해야한다.
.setHomeAddress()에서 값 타입을 가져와 수정하는게 아닌, 새로 객체를 만들어서 하는모습을 볼 수 있다. 위에서 설명한 복사하여 사용하는 예이다.
결론적으로 수정은 .remove()로 삭제를하고 .add()를 해야한다.
그러나 문제가 있다.
쿼리를 보면 .remove()시에 위의 Member와 연관된 Address를 모두지우고 마지막에 insert하는 모습을 볼 수있는데,
이는 값 타입이 식별자 개념이 없기 때문이다.

따라서 실무에선 값 타입 컬렉션을 쓰지않고 대안으로 엔티티를 만드는것이 낫다.


차라리 위처럼 AddressEntity를 생성하여 cascade와 orphan을 함께 사용하여 생명주기를 함께하는것이 더 효율적이다.
값 타입 컬렉션는 그럼 언제쓰는가?
교수님은 값이 변경될때 UPDATE를 할 필요가 없을때, 예를 들어 셀렉트박스에 치킨과 피자를 동시에 클릭하는 경우, 기존 값을 없애고 동시에 관심사를 가져오는경우 즉, 정말 단순한 경우에 쓰신다고 하신다.

* JPQL 페이징

jpql에서 페이징은 .setFirstResult()와 .setMaxResults()두개로만 제한하였기 때문에 위 두가지 메서드를 이용한다.\
* JPQL 조인


위의 예제는 간단한 조인예제인데 join뒤에 on절이 없는것을 확인할 수 있다.
inner join뒤에 m.team으로 JPA엔티티에서 자체적으로 @JoinColumn을 통해 조인을 수행하고 있기때문에(이미 관계가 맺어진 상태이기 때문에) on절이 필요없다.


ON절도 위와 같이 사용할 수 있다. 또한 외부 조인은 Hibernate5.1 부터 가능해졌다. (=아무 연관관계가 없어도 JOIN이 가능하다.)
* JPQL 서브 쿼리

JPA서브 쿼리는 FROM절의 서브 쿼리가 불가능하다.
따라서 조인으로 풀어서 해결가능하면 그렇게 하고, 안된다면 NativeQuery 를 사용하거나 쿼리를 두번날려서 해결한다.
* 엔티티를 직접 사용한 JPQL

where m 과같이 조건절에 직접 엔티티를 사용하면 m.id와 같이 key값을 자동으로 매핑해서 실행하는 것을 볼 수있다.
그렇다면, 외래키 값을 엔티티로 사용하면?

member에 joinColumn으로 연관관계가 있는 team이 있다면 위 또한 자동으로 매핑된다.
* 경로 표현식
경로 표현식은 아래와 같이 3가지 종류가있다


String query = "select m.team From Member m"만약 Member와 Team이 @ManyToOne으로 연관관계가 있다고 가정할때, 위와 같은 쿼리는
묵시적 내부 조인(inner join)이 발생한다.
따라서, 현업에서 위와같은 쿼리는 쿼리튜닝이 힘들기때문에 거대한 어플리케이션에선 묵시적 내부 조인이 일어나지 않도록 하는게 중요하다.
그렇다면 @OneToMany같은 경우는 어떻게 될까?
@Entity
public class Team{
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<>();
...
}
String query = "select t.members From Team t"위와 같이 Team클래스 내부에선 members를 @OneToMany로 양방향 매핑을 하고있다.
String query1 = "select m.Team.teamName From member m" // 단일 값 연관 = 탐색 가능
String query2 = "select t.members.??? From Team t" // 컬렉션 값 = 탐색 불가능위 예제와 같이 query1은 m.Team.teamName으로 Team을 탐색하여 teamName을 가져오는 모습을 확인할수있다.
그러나 query2는 members 즉 , 컬렉션 값이기 때문에 쿼리내에서 .size와 같은 컬렉션 내부 메서드를 호출할뿐 값을 가져 올 순 없다.
착각하지 말아야할 점은 이말은 쿼리내에서만 탐색이 불가능하지 직접 "select t.members From Team t"를 실행했을때 members를 못찾는다는 말은 아니다. 당연하게 양방향 매핑이 되어있기 때문에, 트랜잭션 내에서 조회가 발생했다면 모든 members를 가져온다.
결론적으로 위 query1 이건 query2이건 묵시적으로 내부 조인이 발생하기때문에 즉, 개발자가 모르는 사이에 join이 일어날수있기 때문에 현업에서 사용하지 않아야 한다.
따라서 명시적으로 아래와 같이 조인하여 사용하도록 하는게 맞다.
select m from Member m join m.team t
* fetch join ( 실무에서 매우 많이 사용 )

* fetch조인을 사용하지 않았을때

만약 회원1,2은 팀A, 회원3은 팀B에 있고, 서로 즉시로딩 연관관계일때
위와 같이 System.out.println()하면 member.getTeam()을할때 team을 불러오는 select쿼리를 호출하게 될것이다.
만약 회원이100명이고, 각각 팀이 전부 다른경우 위와같이 출력하게 되면 100번의 쿼리가 실행되는것이다.
이것은 즉시로딩에서 발생하는 N+1과 동일하다고 생각하면 된다.
따라서 즉시 로딩이건 , 지연 로딩이건 호출시점의 차이일뿐이지 N+1은 발생할 수 있다.
* fetch 조인을 사용했을때

fetch 조인을 사용하게 되면 영속성 컨텍스트에 모든 팀을 한번의 호출로 가져오게 된다.
즉, sql로는 아래와 같은 쿼리가 호출된다.

그렇다면 , @OneToMany fetch 조인은 어떻게될까?
String query ="select t From t join fetch t.members";
for(Team team : result) {
System.out.println("team = " + team.getName() + "|members=" + team.getMembers().size());
}팀A는 회원1,2가 있고 팀B는 회원3이 있다고 가정하면 아래와 같은 결과가 나온다.

팀A,B가 정상적으로 찍혔지만 A는 두번 찍힌것을 확인할 수 있다.
즉,. 결과의 값은 온전한 팀의 갯수가아니라 더 많아질수도 있다.

결국 DB입장에선 위와 같은 쿼리가 나가게 되고(WHERE문은 위 예제에 없다고 생각) 일대다관계를 조인했기때문에 여러개의 결과가 당연한 것이다.
그렇다면 위와 같은 중복을 제거할순 없을까?

DISTINCT를 사용하여도 DB입장에서는 두개의 레코드가 서로 다르기때문에 제거가 되지 않는것이 정상이다.
그러나 제거가 된다. 왜냐하면 페치 조인과 DISTINCT를 같이 사용하게 되면 DISTINCT가 추가로 애플리케이션에서 중복 제거를 하기 때문이다.

* 페치 조인과 일반 조인의 차이

위와 같이 JPQL 일반조인은 결과를 반환할 때 연관관계를 고려하지않는다
단지 SELECT절에 지정한 엔티티만 조회할 뿐 팀 엔티티만 조회하고, 회원 엔티티는 조회하지 않는다.

페치 조인은 즉시 로딩과 동일하게 생각하면 되고, SQL한번에 조회한다.
즉, 대부분의 N+1문제는 페치 조인으로 해결할 수 있다.
* 페치 조인의 특징과 한계

먼저, fetch 조인은 따로 조회하는 것이 좋다.
String query = "select t From Team t join fetch t.members m where m.age > 10팀과 연관된 회원이5명이라고 할때, where절에서 별칭으로 조건을걸어 조회하여 3명이 조회되었다고 할때,
이것이 문제가 될수있다는것이다.
어떤곳에서 Team은 5명을 가져오고, 어떤곳에서 Team은 3명을 가져온다면 JPA입장에서는 난감한 상황이 된다.
JPA의 설계 사상자체 , 객체 그래프는 데이터를 모두 조회해야한다.즉, TEAM을 조회했을때 5명의 멤버가 조회되어야 한다.
이럴때는 어떻게하나? 3명의 멤버를 처음부터 가져오는 방식으로 하는게 맞다.
두번째로, 팀,회원,주문같은 관계가 있을때 즉 일대다대다같은 상황에선 페치 조인할 수 없다.
세번째로, 페이징API를 사용할 수 없다.

예를들어 일대다관계,팀A를 조회하여 위와 같은 결과가 도출되었을때 페이징을하여 limit1을 걸었다고 생각해보면,
결과적으로 하나의 데이터가 나오게된다.
이는 첫번째 이유와 동일하게 객체그래프 사상에 맞기않기때문이다.
members는 두개가 되어야하는데 하나만 존재한다는것이 문제가 될수있다.
해결방안으로 아래와 같이 사용할 수 있다.
예를들어보자
String query = "select t From Team t";
List<Team> result = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList()컬렉션을 페치조인을 할수 없기때문에 위처럼 사용하게되면
또 team.getMembers()를 할때마다 지연 로딩으로 N+1이 발생할 수 있다. 즉,성능에 문제가 될 수 있다.
따라서 @BatchSize()를 이용한다.
@Entity
public class Team{
...
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
...
}위와 같이 batchsize를 주고, 다시 같은 쿼리를 실행하게 되면 in쿼리로 size안에 있는 수만큼 넣어주게된다.
즉 in쿼리 내에 멤버1,멤버2를 넣어주게된다.

보통 실무에선 아래와 같이 글로벌하게 셋팅한다고 한다.

* 결론

실무에선 JPA 성능문제의 80%는 N+1이기 때문에, 페치 조인과 배치사이즈를 이용하면 대부분 해결된다고 한다.

3번째의 경우 복잡한 통계데이터 같은 경우라고 생각할수 있는데 아래 2가지 방안이 있을것이다.
1. 엔티티를 페치 조인해서 어플리케이션에서 DTO로 변환한다.
2. 처음부터 JPQL에서 DTO로 지정하여 가져온다.