
이 글은 김영한님의 스프링 고급편 강의중 제목과 관련된 부분을 블로그장의 취향대로 요약한 것이며 강의 자료 및 출처는 가장 아래에서 확인할 수 있습니다.
1. 쓰레드 로컬의 정의
쓰레드 로컬은 해당 쓰레드만 접근할 수 있는 특별한 저장소를 말한다.
예를 들어,여러 사람이 같은 물건 보관 창구를 사용하더라도 창구 직원은 사용자를 인식해서 사용자별로 물건을 구분해준다.
쓰레드 로컬을 사용하지 않는 상황을 떠올려보자.
만약 일반적인 변수 필드가 있다면, 여러 쓰레드가 같은 인스턴스의 필드에 접근할때 처음 쓰레드가 보관한 데이터가 사라질 수 있다.
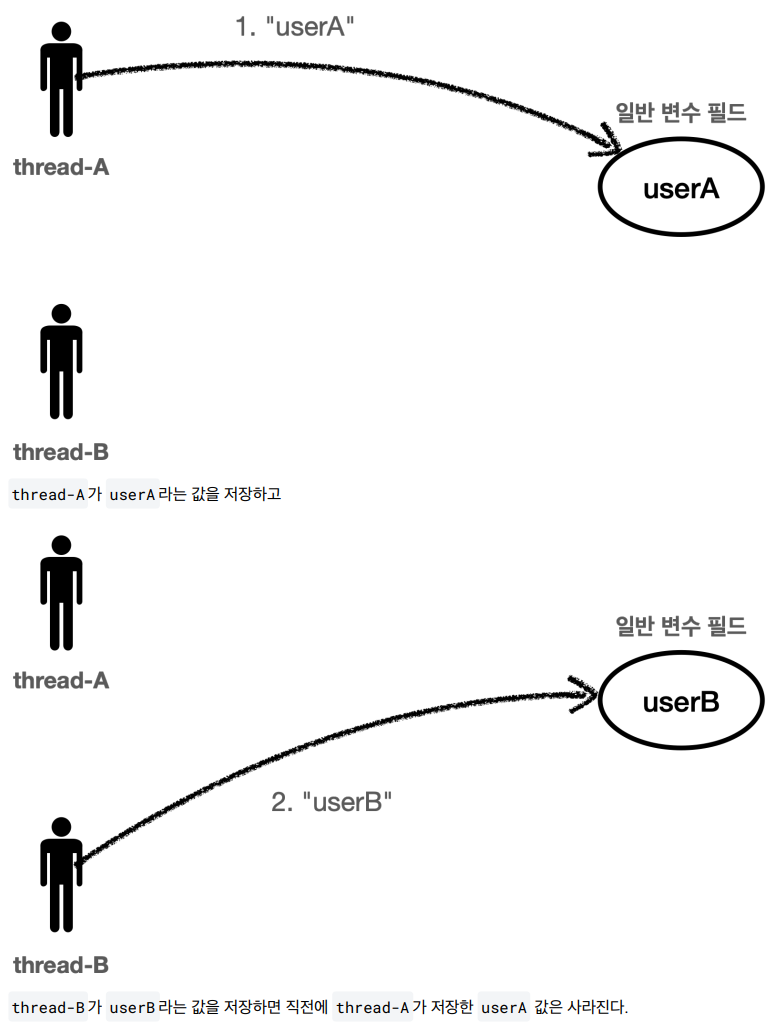
일반 변수 필드는 thread-B가 요청한 순간 필드값 변경요청으로 인해 userA값이 사라진다.
그러나, 쓰레드 로컬을 사용하면 각 쓰레드마다 별도의 내부 저장소를 제공하게 되어 위같은 상황이 발생하지 않는다.
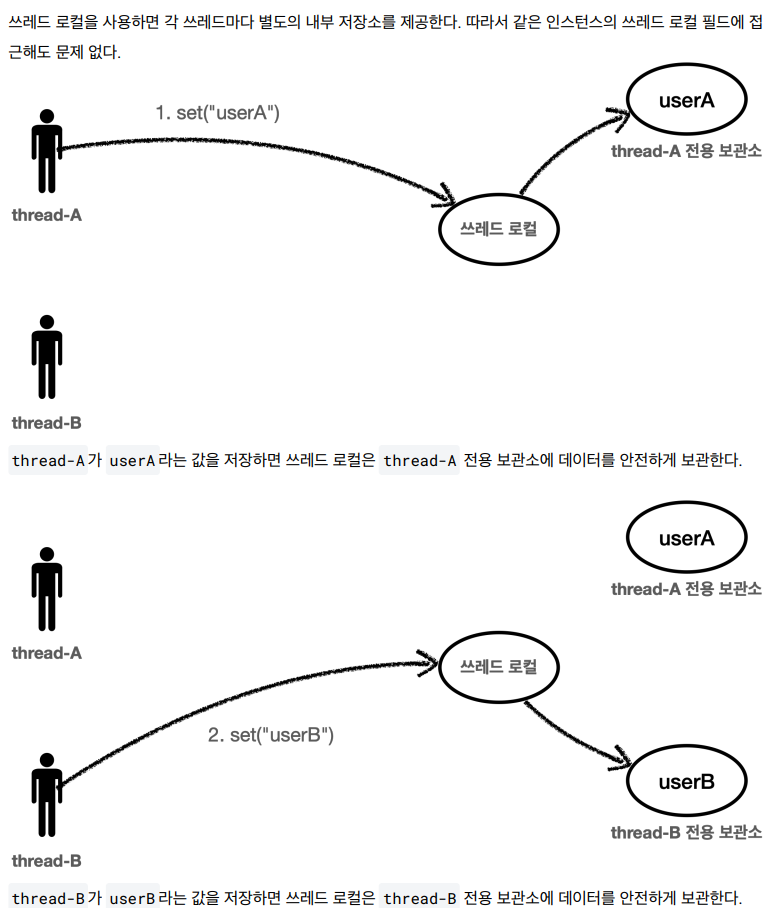
조회할때도 마찬가지로 thread-A가 조회한다면 쓰레드 로컬은 thread-A 전용 보관소에서 userA 데이터를 반환해준다.
비유하자면 쓰레드(사람)이 조회 요청을 한다면 쓰레드 로컬(창구 직원)은 쓰레드 전용 보관소(전용 창구)를 찾아 주는것이다.
2.쓰레드 로컬의 사용 예
2-1. 쓰레드 로컬을 사용하지 않을때
아래 예제를 살펴보자.
@Slf4j
public class FieldService {
private String nameStore;
public String logic(String name){
log.info("저장 name={} -> nameStore={}", name, nameStore);
nameStore = name;
sleep(1000);
log.info("조회 nameStore={}",nameStore);
return nameStore;
}
private void sleep(int millis){
try{
Thread.sleep(millis);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}FieldService는 nameStore필드를 가지고 있고, logic()에서 해당 필드에 데이터를 저장한 뒤, 1초뒤에 읽기 역할을 수행한다.
@Test
void field(){
log.info("main start");
Runnable userA = () -> {
fieldService.logic("userA");
};
Runnable userB = () -> {
fieldService.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start(); //A실행
sleep(2000); // 동시성 문제 발생X
// sleep(100); // 동시성 문제 발생O
threadB.start();
sleep(3000); // 메인 쓰레드 종료 대기
log.info("main exit");
}쓰레드를 sleep(2000) 2초 간격으로 실행하게 되면 문제가 발생하지 않는다.
그러나 sleep(100) 0.1초 간격으로 쓰레드를 실행하게 되면 아래 로그와 같이 문제가 발생한다.

쓰레드A에서 조회된 결과가 userB가 나와버리는 동시성문제가 발생한다.
2-2.쓰레드 로컬을 사용할때
@Slf4j
public class ThreadLocalService {
private ThreadLocal<String> nameStore = new ThreadLocal<>();
public String logic(String name){
log.info("저장 name={} -> nameStore = {}", name , nameStore.get());
nameStore.set(name);
sleep(1000);
log.info("조회 nameStore={}", nameStore.get());
return nameStore.get();
}
private void sleep(int millis){
try{
Thread.sleep(millis);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}쓰레드 로컬을 사용하지 않을때와 달라진것은 필드의 타입을 쓰레드 로컬 형식으로 주었다.
@Test
void threadLocal(){
log.info("main start");
Runnable userA = () -> {
service.logic("userA");
};
Runnable userB = () -> {
service.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start();
sleep(100);
threadB.start();
sleep(2000);
log.info("main exit");
}똑같이 0.1초 간격으로 쓰레드를 실행해본다.

문제가 없이 로그가 출력되는 것을 확인할 수 있다.
3.쓰레드 로컬 사용시 주의사항
쓰레드 로컬의 값을 사용 후 제거하지 않고 그냥 두면 WAS(톰캣)처럼 쓰레드 풀을 사용하는 경우 심각한 문제가 발생할 수 있다.
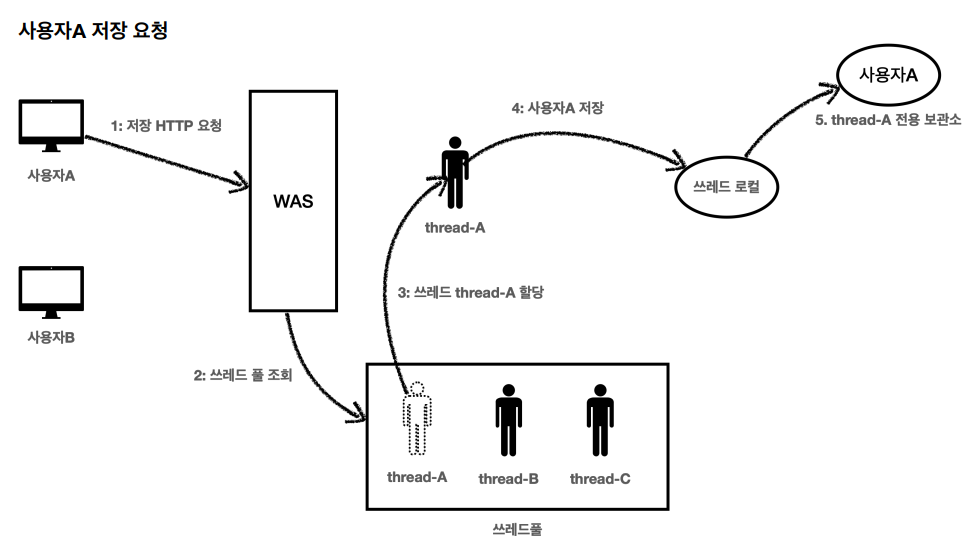
먼저, 저장 요청을하고 전용 보관소에 데이터가 저장되었다.
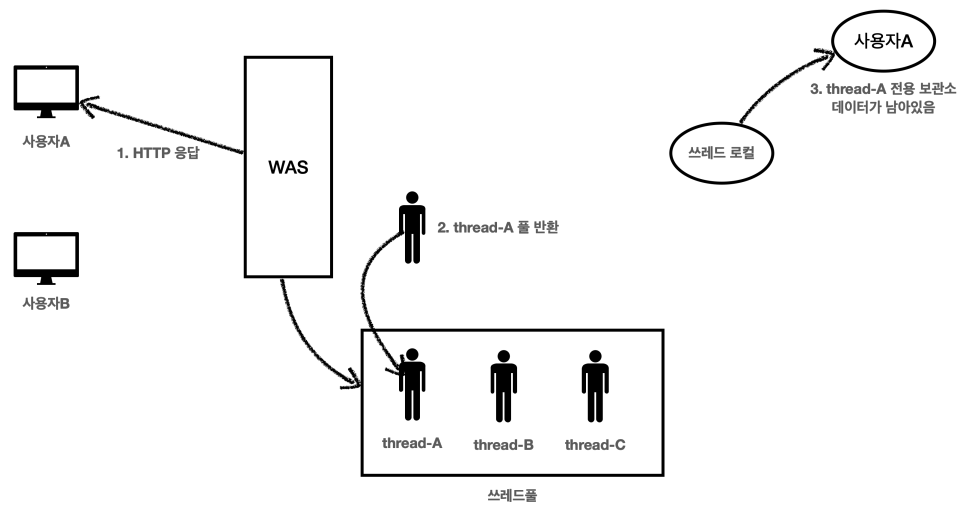
사용자 A의 저장 요청이 종료되었다.
WAS는 자연스럽게 사용이 끝난 쓰레드A를 쓰레드 풀에 반환한다.
여기서 쓰레드A는 쓰레드풀에 아직 살아있기 때문에, 쓰레드 로컬의 쓰레드A 전용 보관소에 사용자A 데이터도 함께 살아있게 된다.
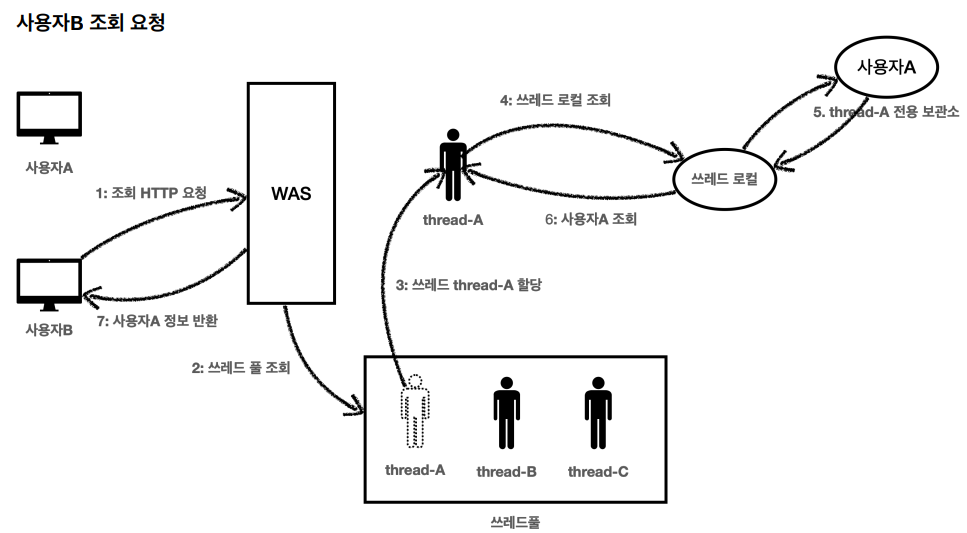
사용자 B의 요청이 들어오면 WAS는 쓰레드 풀에서 쓰레드를 하나 조회하는데 여기서 만약, 쓰레드A가 할당된다면,
쓰레드 로컬은 쓰레드A 전용 보관소에 있는 사용자A 값을 반환한다.
결과적으로 사용자B는 사용자A의 데이터를 확인하게 될 수 있다.
따라서 이런 문제를 예방하려면 사용자A의 요청이 끝날 때, 쓰레드 로컬의 값을 ThreadLocal.remove()를 통해 꼭 제거해줘야 한다.
4.스프링의 실제 사용 예
스프링 DB정리 포스팅에서 트랜잭션 매니져에 관한 설명으로 아래 그림을 예시로 든적이 있다.
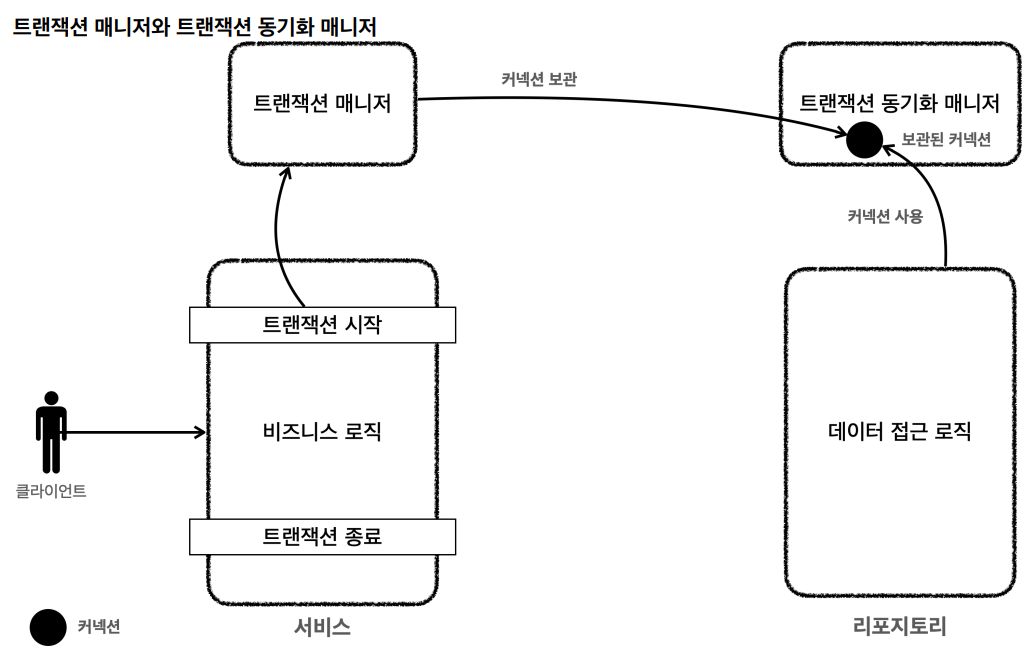
트랜잭션 동기화 매니져가 커넥션을 동기화하는 원리가 쓰레드 로컬을 사용하기 때문이라고 언급한적이 있다.
실제로 스프링은 위와 같이 동기화 매니져를 통해 쓰레드 로컬을 사용하기 때문에 멀티쓰레드 상황에 안전하게 커넥션을 동기화 할 수 있다.
* 출처 자료
스프링 핵심 원리 - 고급편 강의 - 인프런
스프링의 핵심 원리와 고급 기술들을 깊이있게 학습하고, 스프링을 자신있게 사용할 수 있습니다., 핵심 디자인 패턴, 쓰레드 로컬, 스프링 AOP스프링의 3가지 핵심 고급 개념 이해하기 📢 수강
www.inflearn.com
'Spring' 카테고리의 다른 글
| Spring Advanced 정리 3) 프록시 패턴과 데코레이터 패턴 (0) | 2024.03.26 |
|---|---|
| Spring Advanced 정리 2) 템플릿 메서드 패턴과 템플릿 콜백 패턴 (0) | 2024.03.25 |
| Spring DB 정리 4) 트랜잭션 전파 (2) | 2024.03.13 |
| Spring DB 정리 3) 트랜잭션AOP 주의사항과 예외 처리 (0) | 2024.03.06 |
| Spring DB 정리 2) 트랜잭션 처리 및 예외 처리 (0) | 2024.02.13 |
이 글은 김영한님의 스프링 고급편 강의중 제목과 관련된 부분을 블로그장의 취향대로 요약한 것이며 강의 자료 및 출처는 가장 아래에서 확인할 수 있습니다.
1. 쓰레드 로컬의 정의
쓰레드 로컬은 해당 쓰레드만 접근할 수 있는 특별한 저장소를 말한다.
예를 들어,여러 사람이 같은 물건 보관 창구를 사용하더라도 창구 직원은 사용자를 인식해서 사용자별로 물건을 구분해준다.
쓰레드 로컬을 사용하지 않는 상황을 떠올려보자.
만약 일반적인 변수 필드가 있다면, 여러 쓰레드가 같은 인스턴스의 필드에 접근할때 처음 쓰레드가 보관한 데이터가 사라질 수 있다.
일반 변수 필드는 thread-B가 요청한 순간 필드값 변경요청으로 인해 userA값이 사라진다.
그러나, 쓰레드 로컬을 사용하면 각 쓰레드마다 별도의 내부 저장소를 제공하게 되어 위같은 상황이 발생하지 않는다.
조회할때도 마찬가지로 thread-A가 조회한다면 쓰레드 로컬은 thread-A 전용 보관소에서 userA 데이터를 반환해준다.
비유하자면 쓰레드(사람)이 조회 요청을 한다면 쓰레드 로컬(창구 직원)은 쓰레드 전용 보관소(전용 창구)를 찾아 주는것이다.
2.쓰레드 로컬의 사용 예
2-1. 쓰레드 로컬을 사용하지 않을때
아래 예제를 살펴보자.
@Slf4j
public class FieldService {
private String nameStore;
public String logic(String name){
log.info("저장 name={} -> nameStore={}", name, nameStore);
nameStore = name;
sleep(1000);
log.info("조회 nameStore={}",nameStore);
return nameStore;
}
private void sleep(int millis){
try{
Thread.sleep(millis);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}FieldService는 nameStore필드를 가지고 있고, logic()에서 해당 필드에 데이터를 저장한 뒤, 1초뒤에 읽기 역할을 수행한다.
@Test
void field(){
log.info("main start");
Runnable userA = () -> {
fieldService.logic("userA");
};
Runnable userB = () -> {
fieldService.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start(); //A실행
sleep(2000); // 동시성 문제 발생X
// sleep(100); // 동시성 문제 발생O
threadB.start();
sleep(3000); // 메인 쓰레드 종료 대기
log.info("main exit");
}쓰레드를 sleep(2000) 2초 간격으로 실행하게 되면 문제가 발생하지 않는다.
그러나 sleep(100) 0.1초 간격으로 쓰레드를 실행하게 되면 아래 로그와 같이 문제가 발생한다.
쓰레드A에서 조회된 결과가 userB가 나와버리는 동시성문제가 발생한다.
2-2.쓰레드 로컬을 사용할때
@Slf4j
public class ThreadLocalService {
private ThreadLocal<String> nameStore = new ThreadLocal<>();
public String logic(String name){
log.info("저장 name={} -> nameStore = {}", name , nameStore.get());
nameStore.set(name);
sleep(1000);
log.info("조회 nameStore={}", nameStore.get());
return nameStore.get();
}
private void sleep(int millis){
try{
Thread.sleep(millis);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}쓰레드 로컬을 사용하지 않을때와 달라진것은 필드의 타입을 쓰레드 로컬 형식으로 주었다.
@Test
void threadLocal(){
log.info("main start");
Runnable userA = () -> {
service.logic("userA");
};
Runnable userB = () -> {
service.logic("userB");
};
Thread threadA = new Thread(userA);
threadA.setName("thread-A");
Thread threadB = new Thread(userB);
threadB.setName("thread-B");
threadA.start();
sleep(100);
threadB.start();
sleep(2000);
log.info("main exit");
}똑같이 0.1초 간격으로 쓰레드를 실행해본다.
문제가 없이 로그가 출력되는 것을 확인할 수 있다.
3.쓰레드 로컬 사용시 주의사항
쓰레드 로컬의 값을 사용 후 제거하지 않고 그냥 두면 WAS(톰캣)처럼 쓰레드 풀을 사용하는 경우 심각한 문제가 발생할 수 있다.
먼저, 저장 요청을하고 전용 보관소에 데이터가 저장되었다.
사용자 A의 저장 요청이 종료되었다.
WAS는 자연스럽게 사용이 끝난 쓰레드A를 쓰레드 풀에 반환한다.
여기서 쓰레드A는 쓰레드풀에 아직 살아있기 때문에, 쓰레드 로컬의 쓰레드A 전용 보관소에 사용자A 데이터도 함께 살아있게 된다.
사용자 B의 요청이 들어오면 WAS는 쓰레드 풀에서 쓰레드를 하나 조회하는데 여기서 만약, 쓰레드A가 할당된다면,
쓰레드 로컬은 쓰레드A 전용 보관소에 있는 사용자A 값을 반환한다.
결과적으로 사용자B는 사용자A의 데이터를 확인하게 될 수 있다.
따라서 이런 문제를 예방하려면 사용자A의 요청이 끝날 때, 쓰레드 로컬의 값을 ThreadLocal.remove()를 통해 꼭 제거해줘야 한다.
4.스프링의 실제 사용 예
스프링 DB정리 포스팅에서 트랜잭션 매니져에 관한 설명으로 아래 그림을 예시로 든적이 있다.
트랜잭션 동기화 매니져가 커넥션을 동기화하는 원리가 쓰레드 로컬을 사용하기 때문이라고 언급한적이 있다.
실제로 스프링은 위와 같이 동기화 매니져를 통해 쓰레드 로컬을 사용하기 때문에 멀티쓰레드 상황에 안전하게 커넥션을 동기화 할 수 있다.
* 출처 자료
스프링 핵심 원리 - 고급편 강의 - 인프런
스프링의 핵심 원리와 고급 기술들을 깊이있게 학습하고, 스프링을 자신있게 사용할 수 있습니다., 핵심 디자인 패턴, 쓰레드 로컬, 스프링 AOP스프링의 3가지 핵심 고급 개념 이해하기 📢 수강
www.inflearn.com
'Spring' 카테고리의 다른 글
| Spring Advanced 정리 3) 프록시 패턴과 데코레이터 패턴 (0) | 2024.03.26 |
|---|---|
| Spring Advanced 정리 2) 템플릿 메서드 패턴과 템플릿 콜백 패턴 (0) | 2024.03.25 |
| Spring DB 정리 4) 트랜잭션 전파 (2) | 2024.03.13 |
| Spring DB 정리 3) 트랜잭션AOP 주의사항과 예외 처리 (0) | 2024.03.06 |
| Spring DB 정리 2) 트랜잭션 처리 및 예외 처리 (0) | 2024.02.13 |