
Numpy 간단한 배열 생성

pandas 데이터 선택하기
예제로 쓸 데이터프레임 생성
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
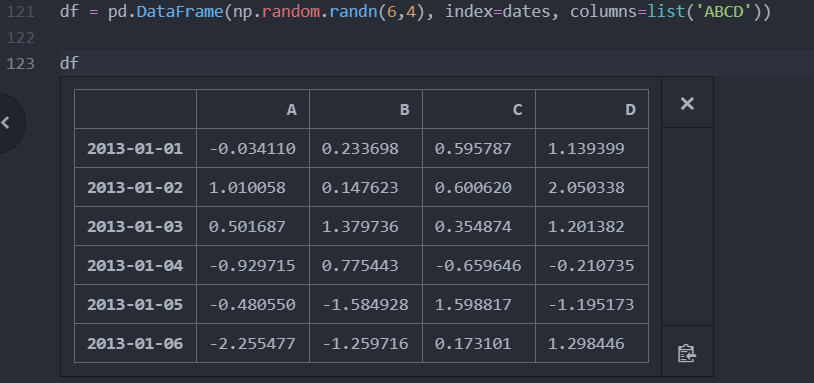
이름을 이용하여 선택 : .loc
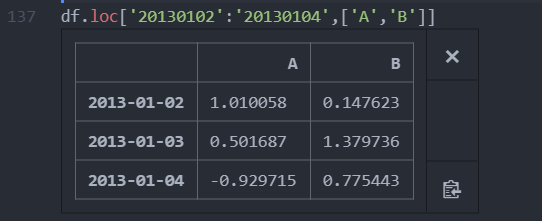
위치를 이용하여 선택: .iloc
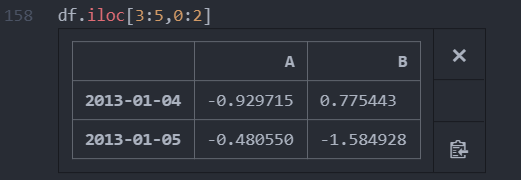
ex)네 번째 행과 다섯 번째 행,첫 번째 열과 두 번째 열 선택
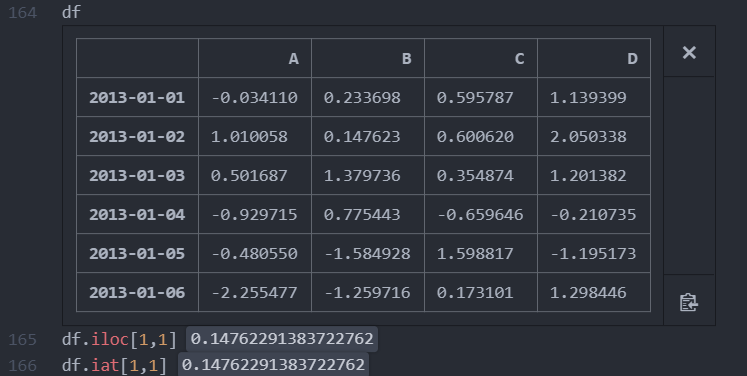
값 하나를 선택
df.iloc[1,1] 또는 df.iat[1,1]
2행과 2열에 있는 요소 선택
조건을 이용
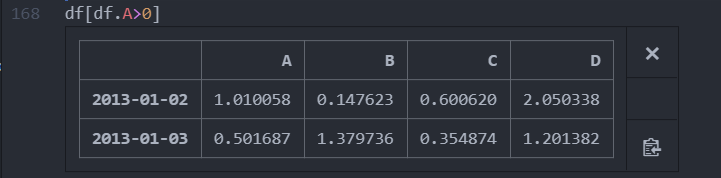
df[df.A > 0]
A라는 열에 있는 값이 양수인 경우 해당 행들을 선택
df[df > 0]
조건에 맞지 않는 값들은 결측치 NaN으로 보여짐

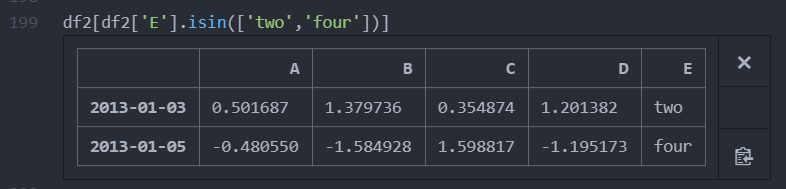
필터링이 필요할 경우 -> isin()을 사용
1. 새로운 열 추가
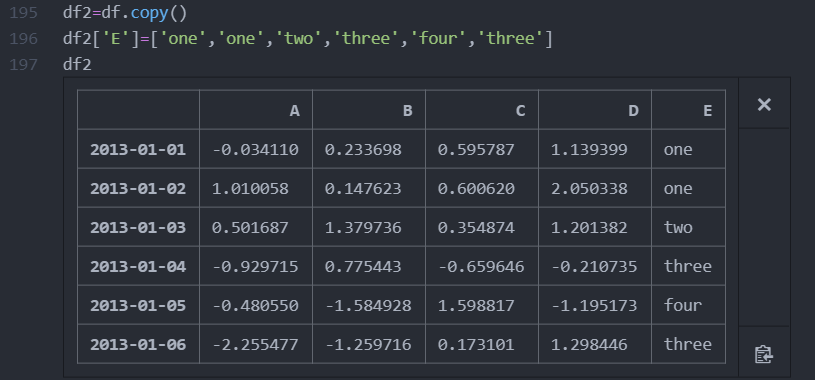
2.isin을 사용하여 내용을 충족하는 행을 가져옴
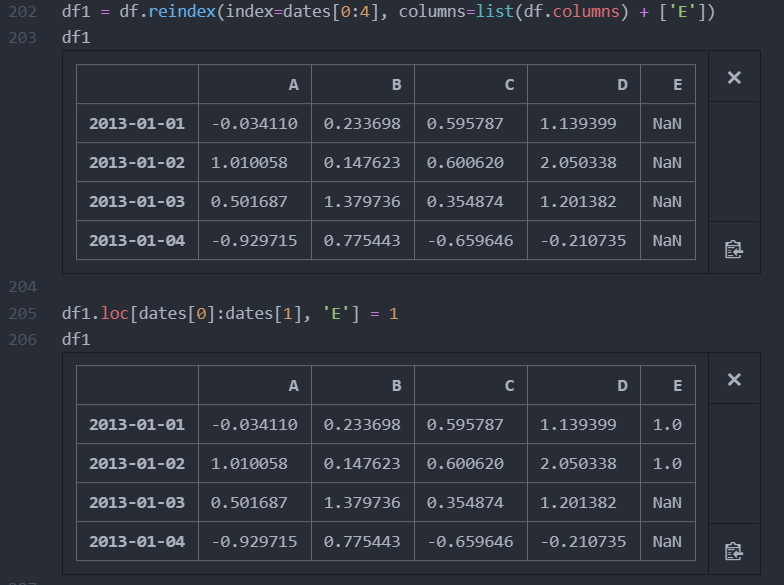
reindex : 해당 축에 대하여 인덱스를 변경/추가/삭제
'E'열을 추가한뒤 첫 번째 행과 두 번째 행을 1로 설정
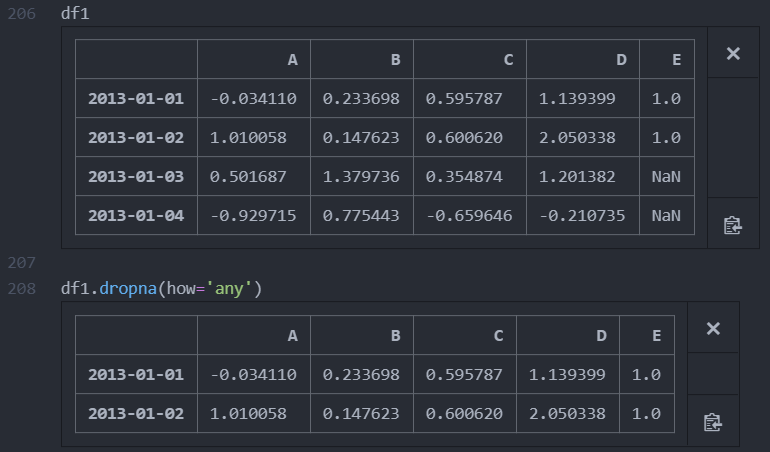
결측치가 존재하는 행을 삭제 dropna()
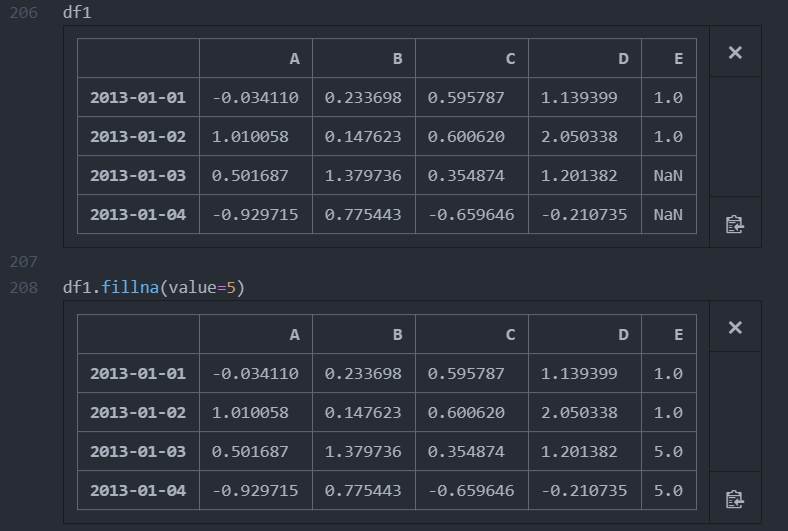
결측치가 있는 부분을 다른 값으로 채움 fillna()
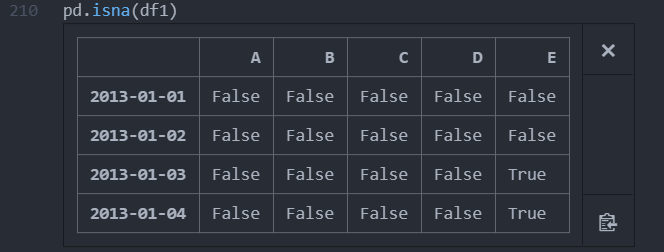
결측치의 여부 : isna()
'인공지능 교육 > Python' 카테고리의 다른 글
| zip() 함수 (0) | 2021.07.10 |
|---|---|
| 파이썬에서 self를 쓰는 이유, TypeError: hello() takes 0 positional arguments but 1 was given (0) | 2021.07.10 |
| numpy,집합적사고,List와 Array의 차이 (0) | 2021.06.28 |
| 셀레늄 설치 및 사용 (0) | 2021.06.24 |
| Python 정수->리스트, 문자열->리스트 변환 (0) | 2021.06.22 |