
1. 패션 MNIST 데이터셋 저장

load_data()는 훈련 데이터와 테스트 데이터를 나누어 반환함

28x28크기인 이미지가 6만개 있고, 타깃은 1차원 배열에 6만개의 원소가 있다
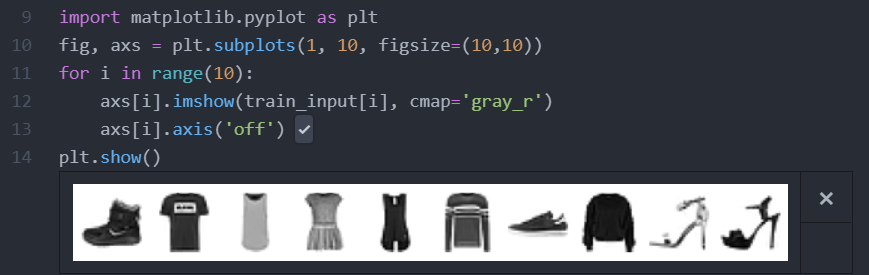
훈련 데이터에서 몇 개의 샘플을 그림으로 출력

처음 10개 샘플의 타깃값을 리스트로 만든 후 출력
패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성되어있으며, 앞서 출력한 이미지를 보면 마지막 5,5는 같은
종류의 신발이란 것을 알수있다.

넘파이 unique() 함수로 레이블 당 샘플 개수를 확인
0~9까지 레이블마다 정확히 6,000개의 샘플이 들어 있는 것을 볼 수 있다.
2. 로지스틱 회귀로 패션 아이템 분류

1. reshape() 메서드를 사용해 2차원 배열인 각 샘플을 1차원 배열로 펼친다. (SGDClassifier 는 2차원 입력을 다루지 못하기 때문에 각 샘플을 1차원 배열로 만든다)
2. reshape()메서드의 두 번째 매개변수를 28*28이미지 크기에 맞게 지정하면 첫 번째 차원(샘플 개수)은 변하지 않고 원본 데이터의 두 번째, 세 번째 차원이 1차원으로 합쳐진다.

784개의 픽셀로 이루어진 60,000개의 샘플을 준비했다.
SGDClassifier 클래스와 cross_vaildate 함수를 사용하여 이 데이터에서 교차 검증으로 성능을 확인

아직 만족할 만한 수준이 아닌것을 알 수 있다.
가장 간단한 인공 신경망 : 확률적 경사 하강법을 사용한 로지스틱 회귀 모델
더 좋은 성능?
인공 신경망 모델을 만드는 최신 라이브러리들은 SGDClassifier에 없는 몇 가지 기능을 제공한다.
가장 인기가 높은 딥러닝 라이브러리 : 텐서플로
3. 인공 신경망으로 모델 만들기
로지스틱 회귀에서는 교차 검증으로 모델을 평가하지만, 인공 신경망에서는 검증 세트를 별도로 덜어내 사용하는 이유
1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적
2. 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸림

사이킷 런의 train_test_split()함수를 사용하여 훈련 세트에서 20%를 검증 세트로 덜어내었다.

케라스의 레이어 패키지 안에는 다양한 층이 준비되어 있다.
가장 기본이 되는 층 : 밀집층(dense player)
케라스의 Dense 클래스를 사용해 밀집층을 생성

10=뉴런개수 actiavation=뉴런의 출력에 적용할 함수 input_shape=입력의 크기
10개의 뉴런이라면 소프트맥스 함수를 쓴다. -> 다중 분류는 소프트맥스 함수를 쓴다
만약 2개의 클래스를 분류하는 이진 분류라면 시그모이드 함수를 사용한다.
input_shape는 10개의 뉴런이 각각 몇 개의 입력을 받는지 튜플로 지정한다.

객체를 만들 때 앞에서 만든 밀집층의 객체 dense 를 전달
모델을 만들 때 절편이 뉴런마다 더해짐
소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수를 활성화 함수라고 부름
4. 인공 신경망으로 패션 아이템 분류

compile()메서드는 케라스 모델의 훈련하기 전 설정 단계라고 보면된다.
이진 분류 : loss='binary_crossentropy'
다중 분류 : loss='categorical_crossentropy'
케라스는 모델이 훈련할 때 기본으로 에포크마다 손실 값을 출력해 준다.
손실이 줄어들면 훈련이 잘되었다는 것을 알 수 있지만 정확도를 함께 출력하면 더 좋다.
이를 위해 metrics 매개변수에 정확도 지표를 의미하는 'accuracy'를 지정한다.
원-핫 인코딩 : 타깃값을 해당 클래스만 1이고 나머지는 모두 0인 배열로 만드는 것
다중 분류에서 크로스 엔트로피 손실 함수를 사용하려면 0,1,2와 같이 정수로된 타깃값을 원-핫 인코딩으로 변환해야 함

모두 정수로 되어 있는것을 볼 수 있다.
그러나 텐서플로에선 정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 그냥 사용할 수 있다.
모델을 훈련
훈련하는 fit()메서드는 사이킷런과 비슷
처음 두 매개변수에 입력(train_scaled)과 타깃(train_target)을 지정한다.
그다음 반복할 에포크 횟수를 epochs 매개변수에 지정한다.
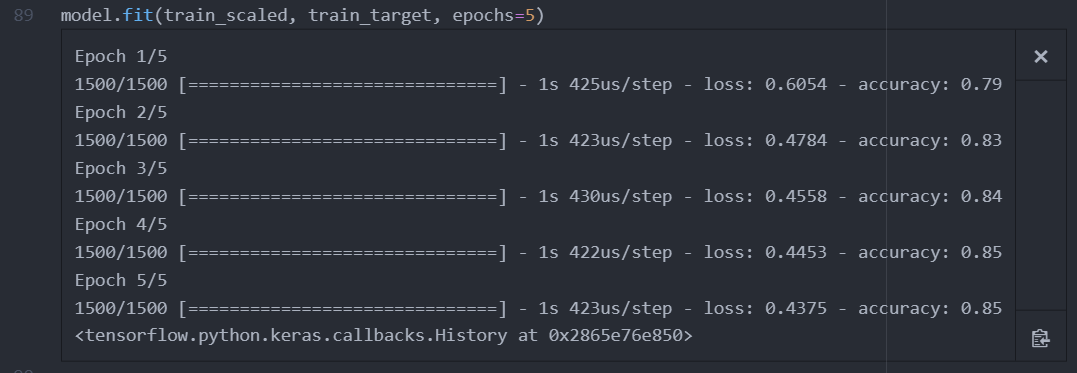
5번 반복에 정확도가 85%에 임박하여 전 모델보다 나아진것을 볼 수 있다.
케라스에서 모델의 성능을 평가하는 메서드 : evaluate()

사이킷런 모델
모델 -> sc = SGDClassifier(loss='log', max_iter=5) # loss는 손실 함수, max_iter는 반복 횟수
훈련 -> sc.fit(train_scaled, train_target)
평가 -> sc.score(val_scaled, val_target)
케라스 모델
dense = keras.layers.Dense(10, activation='softmax', input_shape(784,)) # 층 생성
모델 -> model = keras.Sequential(dense)
model.comile(loss='sparse_categorical_crossentropy', metrics='accuracy')
훈련 -> model.fit(train_scaled, train_target, epochs=5)
평가 -> model.evaluate(val_scaled, val_target)
★ TensorFlow 정리
1.Dense는 신경망에서 가장 기본 층인 밀집층을 만드는 클래스
첫 번째 매개변수 : 뉴런의 개수
두 번째 매개변수(activation 매개변수) : 사용할 활성화 함수를 지정 ex) sigmoid,softmax
2.Sequential은 케라스에서 신경망 모델을 만드는 클래스
이 클래스의 객체를 생성할 때 신경망 모델에 추가할 층을 지정할 수 있음.
3.compile()은 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
loss 매개변수에 손실 함수를 지정
이진 분류 : binary_crossentropy
다중 분류 : sparse_categorical_crossentropy
회귀 모델 : mean_square_error
metrics 매개변수에 훈련 과정에서 측정하고 싶은 지표를 지정 ex)accuracy로 정확도를 측정
4.fit()은 모델을 훈련하는 메서드
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달
epochs 매개변수에 전체 데이터에 대해 반복할 에포크 횟수를 지정
5.evaluate()는 모델 성능을 평가하는 메서드
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달
compile() 메서드에서 loss 매개변수에 지정한 손실 함수의 값과 metrics 매개변수에서 지정한 측정 지표를 출력
'인공지능 교육 > 머신러닝' 카테고리의 다른 글
| Ridge 회귀, Linear 회귀 (0) | 2021.07.09 |
|---|---|
| np.random.seed,코딩에 있어서의 랜덤,pseudo랜덤 (0) | 2021.07.08 |
1. 패션 MNIST 데이터셋 저장
load_data()는 훈련 데이터와 테스트 데이터를 나누어 반환함
28x28크기인 이미지가 6만개 있고, 타깃은 1차원 배열에 6만개의 원소가 있다
훈련 데이터에서 몇 개의 샘플을 그림으로 출력
처음 10개 샘플의 타깃값을 리스트로 만든 후 출력
패션 MNIST의 타깃은 0~9까지의 숫자 레이블로 구성되어있으며, 앞서 출력한 이미지를 보면 마지막 5,5는 같은
종류의 신발이란 것을 알수있다.
넘파이 unique() 함수로 레이블 당 샘플 개수를 확인
0~9까지 레이블마다 정확히 6,000개의 샘플이 들어 있는 것을 볼 수 있다.
2. 로지스틱 회귀로 패션 아이템 분류
1. reshape() 메서드를 사용해 2차원 배열인 각 샘플을 1차원 배열로 펼친다. (SGDClassifier 는 2차원 입력을 다루지 못하기 때문에 각 샘플을 1차원 배열로 만든다)
2. reshape()메서드의 두 번째 매개변수를 28*28이미지 크기에 맞게 지정하면 첫 번째 차원(샘플 개수)은 변하지 않고 원본 데이터의 두 번째, 세 번째 차원이 1차원으로 합쳐진다.
784개의 픽셀로 이루어진 60,000개의 샘플을 준비했다.
SGDClassifier 클래스와 cross_vaildate 함수를 사용하여 이 데이터에서 교차 검증으로 성능을 확인
아직 만족할 만한 수준이 아닌것을 알 수 있다.
가장 간단한 인공 신경망 : 확률적 경사 하강법을 사용한 로지스틱 회귀 모델
더 좋은 성능?
인공 신경망 모델을 만드는 최신 라이브러리들은 SGDClassifier에 없는 몇 가지 기능을 제공한다.
가장 인기가 높은 딥러닝 라이브러리 : 텐서플로
3. 인공 신경망으로 모델 만들기
로지스틱 회귀에서는 교차 검증으로 모델을 평가하지만, 인공 신경망에서는 검증 세트를 별도로 덜어내 사용하는 이유
1. 딥러닝 분야의 데이터셋은 충분히 크기 때문에 검증 점수가 안정적
2. 교차 검증을 수행하기에는 훈련 시간이 너무 오래 걸림
사이킷 런의 train_test_split()함수를 사용하여 훈련 세트에서 20%를 검증 세트로 덜어내었다.
케라스의 레이어 패키지 안에는 다양한 층이 준비되어 있다.
가장 기본이 되는 층 : 밀집층(dense player)
케라스의 Dense 클래스를 사용해 밀집층을 생성
10=뉴런개수 actiavation=뉴런의 출력에 적용할 함수 input_shape=입력의 크기
10개의 뉴런이라면 소프트맥스 함수를 쓴다. -> 다중 분류는 소프트맥스 함수를 쓴다
만약 2개의 클래스를 분류하는 이진 분류라면 시그모이드 함수를 사용한다.
input_shape는 10개의 뉴런이 각각 몇 개의 입력을 받는지 튜플로 지정한다.
객체를 만들 때 앞에서 만든 밀집층의 객체 dense 를 전달
모델을 만들 때 절편이 뉴런마다 더해짐
소프트맥스와 같이 뉴런의 선형 방정식 계산 결과에 적용되는 함수를 활성화 함수라고 부름
4. 인공 신경망으로 패션 아이템 분류
compile()메서드는 케라스 모델의 훈련하기 전 설정 단계라고 보면된다.
이진 분류 : loss='binary_crossentropy'
다중 분류 : loss='categorical_crossentropy'
케라스는 모델이 훈련할 때 기본으로 에포크마다 손실 값을 출력해 준다.
손실이 줄어들면 훈련이 잘되었다는 것을 알 수 있지만 정확도를 함께 출력하면 더 좋다.
이를 위해 metrics 매개변수에 정확도 지표를 의미하는 'accuracy'를 지정한다.
원-핫 인코딩 : 타깃값을 해당 클래스만 1이고 나머지는 모두 0인 배열로 만드는 것
다중 분류에서 크로스 엔트로피 손실 함수를 사용하려면 0,1,2와 같이 정수로된 타깃값을 원-핫 인코딩으로 변환해야 함
모두 정수로 되어 있는것을 볼 수 있다.
그러나 텐서플로에선 정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 그냥 사용할 수 있다.
모델을 훈련
훈련하는 fit()메서드는 사이킷런과 비슷
처음 두 매개변수에 입력(train_scaled)과 타깃(train_target)을 지정한다.
그다음 반복할 에포크 횟수를 epochs 매개변수에 지정한다.
5번 반복에 정확도가 85%에 임박하여 전 모델보다 나아진것을 볼 수 있다.
케라스에서 모델의 성능을 평가하는 메서드 : evaluate()
사이킷런 모델
모델 -> sc = SGDClassifier(loss='log', max_iter=5) # loss는 손실 함수, max_iter는 반복 횟수
훈련 -> sc.fit(train_scaled, train_target)
평가 -> sc.score(val_scaled, val_target)
케라스 모델
dense = keras.layers.Dense(10, activation='softmax', input_shape(784,)) # 층 생성
모델 -> model = keras.Sequential(dense)
model.comile(loss='sparse_categorical_crossentropy', metrics='accuracy')
훈련 -> model.fit(train_scaled, train_target, epochs=5)
평가 -> model.evaluate(val_scaled, val_target)
★ TensorFlow 정리
1.Dense는 신경망에서 가장 기본 층인 밀집층을 만드는 클래스
첫 번째 매개변수 : 뉴런의 개수
두 번째 매개변수(activation 매개변수) : 사용할 활성화 함수를 지정 ex) sigmoid,softmax
2.Sequential은 케라스에서 신경망 모델을 만드는 클래스
이 클래스의 객체를 생성할 때 신경망 모델에 추가할 층을 지정할 수 있음.
3.compile()은 모델 객체를 만든 후 훈련하기 전에 사용할 손실 함수와 측정 지표 등을 지정하는 메서드
loss 매개변수에 손실 함수를 지정
이진 분류 : binary_crossentropy
다중 분류 : sparse_categorical_crossentropy
회귀 모델 : mean_square_error
metrics 매개변수에 훈련 과정에서 측정하고 싶은 지표를 지정 ex)accuracy로 정확도를 측정
4.fit()은 모델을 훈련하는 메서드
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달
epochs 매개변수에 전체 데이터에 대해 반복할 에포크 횟수를 지정
5.evaluate()는 모델 성능을 평가하는 메서드
첫 번째와 두 번째 매개변수에 입력과 타깃 데이터를 전달
compile() 메서드에서 loss 매개변수에 지정한 손실 함수의 값과 metrics 매개변수에서 지정한 측정 지표를 출력
'인공지능 교육 > 머신러닝' 카테고리의 다른 글
| Ridge 회귀, Linear 회귀 (0) | 2021.07.09 |
|---|---|
| np.random.seed,코딩에 있어서의 랜덤,pseudo랜덤 (0) | 2021.07.08 |